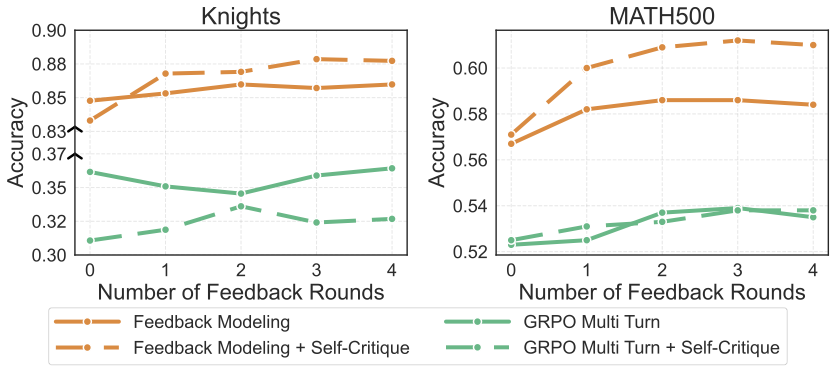
Ablation: Text Feedback vs. Correctness-Only Feedback
A key question is whether the semantic richness of text feedback matters, or whether simply knowing correctness is sufficient. We compare RLTF-SD using full text critiques against a correctness-only baseline that replaces the judge's critique with a simple sentence: "Your previous answer was {correct/incorrect}".
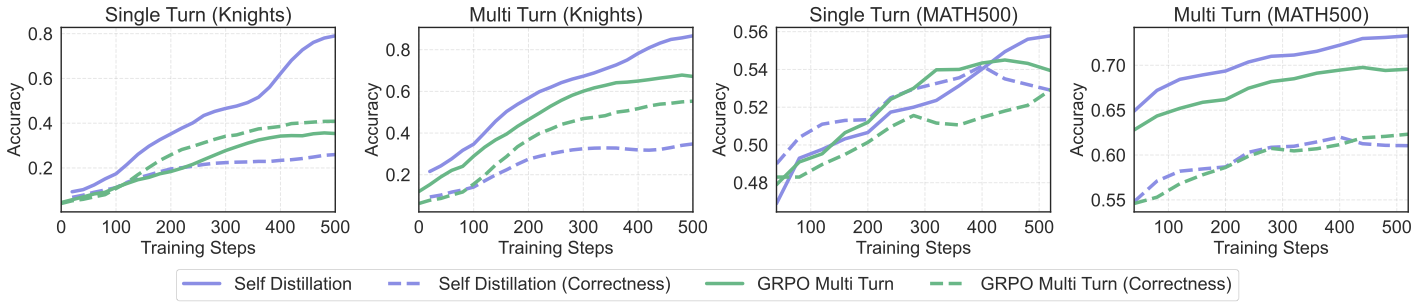
Figure: Evaluation curves on Knights and Knaves and MATH500 (trained on DAPO) for text feedback vs. correctness-only feedback. We compare single- and multi-turn accuracy on two algorithms: multi-turn GRPO and RLTF-SD. Overall, using text feedback outperforms using correctness-only feedback for single-turn and multi-turn accuracy on both algorithms.
Key findings:
- The correctness-only baseline does not perform well compared to RLTF-SD with full text feedback, indicating that semantically rich text feedback is critical.
- One notable exception is the single-turn Knights and Knaves accuracy using multi-turn GRPO. Without distillation, neither text feedback nor correctness-only feedback can significantly influence the model's first-turn response, so there is little difference between the two in this setting.